هدف عالمي من لياو للميلان 🔥😳مباراة ليفربول وأس ميلان
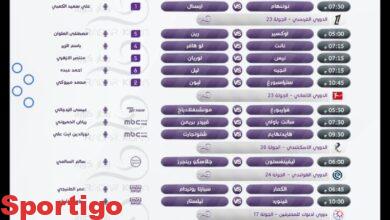
مباراة اليوم
ملخص مباريات اليوم
اهداف اليوم
لمن فاته مباريات اليوم
بث مباشر مباريات اليوم
مباريات اليوم بث مباشر
جميع أهداف اليوم
تحليل مباريات اليوم
هدف محمد صلاح
هدف محمد صلاح ضد
هدف محمد صلاح امس
هدف محمد صلاح يوم
هدف محمد صلاح الان
هدف محمد صلاح اليوم
هدف محمد صلاح الاخير
هدف محمد صلاح يوم
مباراة اليوم
ملخص المباراةهدف ميلان الاول في ليفربول
الهدف الاول لميلان في مرمي ليفربول
هدف اول ميلان ضد ليفربول
اهداف مباراة ليفربول وميلان اليوم
اهداف مباراه ليفربول و ميلان
أهداف مباريات اليوم
#اهداف_ليفربول_اليوم
#هدف_ليفربول_اليوم
#جول_فاصل
#هدف_محمد_صلاح_اليوم
#اهداف_مباريات_اليوم
#ليفربول_ضد_ميلان
#ليفربول
(FB_VID ID = “23978347075161506” Reel = “1”)
#هدف #عالمي #من #لياو #للميلان #مباراة #ليفربول #واس #ميلان..